아파치 카프카 is a viable choice to a traditional messaging system. It started as an interior system created by Linkedin to take care of 1.4 trillion everyday messages. Nonetheless, today it’s an open-source data streaming system that can satisfy a variety of organization needs.
Apache Kafka?
아파치 카프카 is an open data store developed to process and ingest streaming data in real-time. Streaming data is frequently generated by various information resources that normally send out information documents all at once. As a result, a streaming platform need to cope with this continuous circulation of information as well as procedure the data incrementally and in a sequence
아파치 카프카 can produce real-time streaming pipes for information and also applications that stream in real-time. Information pipelines are trusted in handling and moving the data in between one tool and the following, and also a streaming app can be called an app that takes in a stream of data. For instance, if you would like to create a data pipe that takes the information from user task to keep an eye on exactly how customers browse your site in real-time. Apache Kafka( 아파치 카프카) would be used to shop and consume streaming information and offer analyses to the applications that run your information pipe. Kafka is additionally regularly made use of as a message broker that serves as a framework that handles and also facilitates interaction between two applications.
What is the process behind the Kafka function?
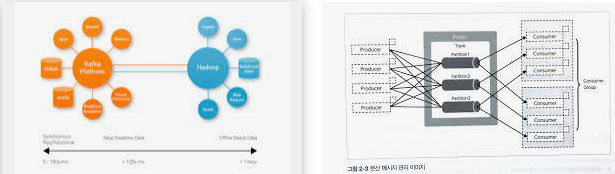
Kafka includes two messaging models that are queuing and also publish-subscribe, delivering the major advantages of both to customers. Queuing makes it possible for the handling of information to spread out across multiple instances of the consumer, making it incredibly flexible. But typical queues aren’t multi-subscriber. The strategy of publishing-subscribe is multi-subscriber. Nevertheless, because every message goes to each subscriber, it can’t spread out work throughout different employee processes. Apache Kafka( 아파치 카프카) utilizes the separated log design to link both of these services. Logs are an ordered sequence of records. The logs are divided right into partitions or segments representing various clients. There might be many clients to a comparable subject, as well as each one is designated a separate department that allows for higher ability. Furthermore, Kafka’s model allows replayability, which allows numerous independent applications that check out data streams to operate individually at their very own pace.
The benefits of Apache Kafka’s method
Scalable.
Kafka’s separated log version enables details to be topped numerous servers, making it scalable past what could be accommodated on one web server.
Fast.
Kafka is a data stream decoupler that has very reduced latency. So, This makes it extremely reliable.
Resilient.
Partitions are duplicated and distributed over several servers. On top of that, the data is contacted the disk. This shields versus servers’ failure, which makes the information robust and also reputable.